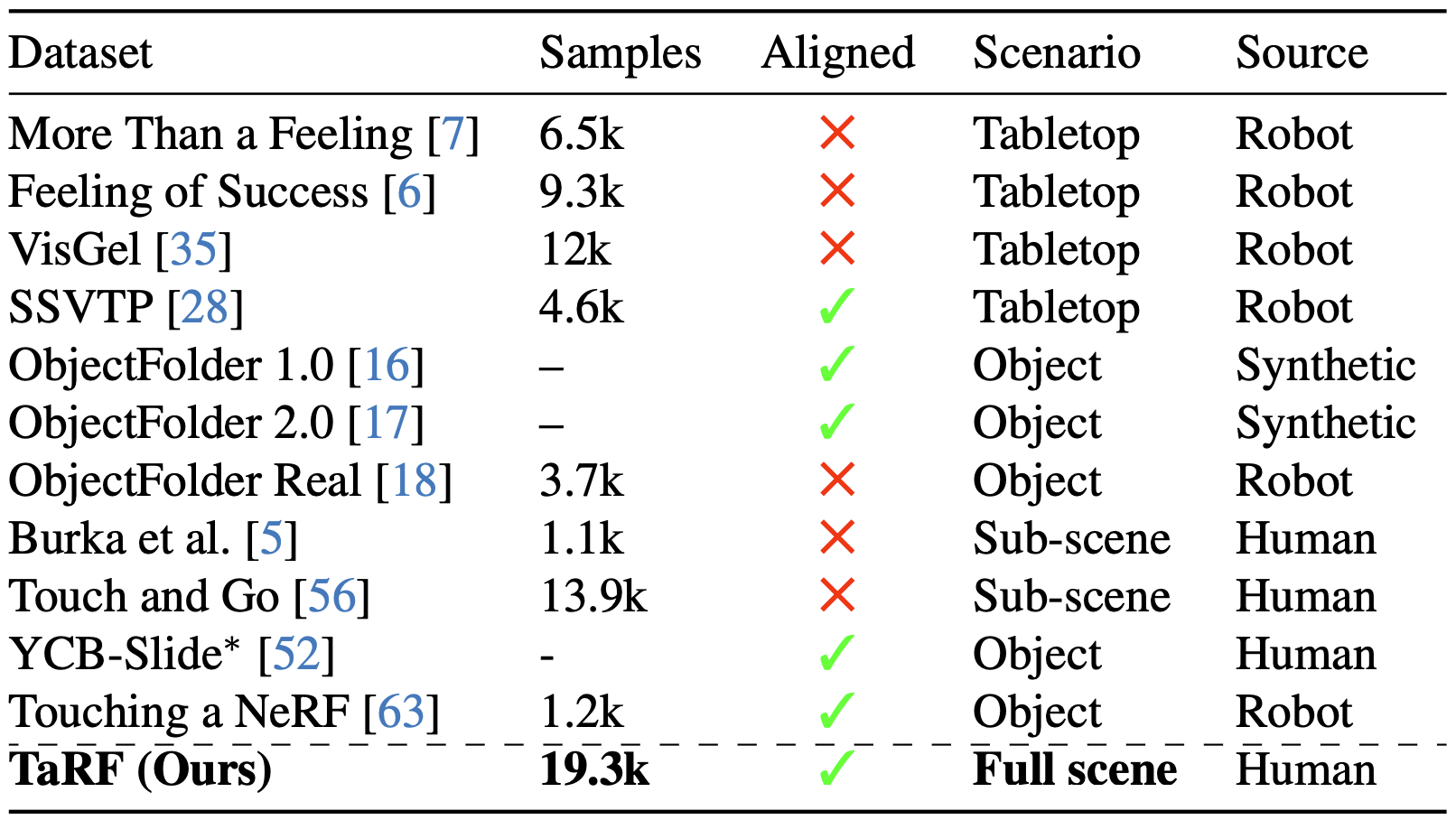
Capturing Vision and Touch Signals
Capturing Setup
We mount an RGB-D camera to one end of a rod, and a tactile sensor to the other end. Next, record temporally-aligned vision-touch pairs. The relative pose between the camera and the tactile sensor is solved by using visual-tactile correspondences. Since the camera and the tactile sensor are approximately orthogonal, we first synthesize a novel view by rotating the camera 90° on the x-axis and then manually annotate the correspondences between the touch measurement and synthesized frame.

The calibration procedure of estimating the 6DoF relative pose \( ({\mathbf R}, {\mathbf t}) \) between the camera and the tactile sensor is formulated as a resectioning problem. We obtain 3D points \( \{\mathbf{x}_i\}_{i=1}^M \) for each annotated correspondences. Each point has a pixel position \( \mathbf{u}_i \in \mathcal{R}^2\) in the touch measurement. We find \( ({\mathbf R}, {\mathbf t}) \) by minimizing the reprojection error:
\( \min_{{\mathbf R}, {\mathbf t}} \frac{1}{M}\sum_{i=1}^M \lVert \pi({\mathbf K}[\mathbf{R}\,\,|\,\,\mathbf{t}], \mathbf{X}_i) - \mathbf{u}_i \rVert_1, \)
where \( \pi \) is the perspective projection matrix, \( \mathbf{K} \) is the intrinsics of the tactile sensor's camera, and the point \( \mathbf{X}_i \) is in the coordinate system of the generated vision frame.
A 3D Visual-Tactile Dataset
First, we collect multiple views from the scene around the areas we plan to touch. Next, we collect synchronized visual and touch data.
We then estimate the camera location of the vision frames collected in the previous two stages using SfM. After estimating the camera poses for the vision frames, the touch measurements' poses can be derived by using the relative pose. Finally, we associate each touch sensor with a color image by translating the sensor poses upwards and querying the NeRF with such poses. Note that the white box on the center of the visual image corresponds to the touched area.

Compared to previous works, our dataset is the first to capture quasi-dense, scene-level, and spatially-aligned visual-tactile data. We call the resulting scene representation a tactile-augmented radiance field (TaRF).
Imputing Missing Touch
Method Overview
With the captured dataset, we train a diffusion model to estimate touch at locations not directly probed by a sensor. The model is conditioned on the egocentric visual images and depth maps extracted from the NeRF. Through the touch estimation, the model effectively propagates sparse touch samples, obtained by probing, to other visually/structurally similar regions of the scene.
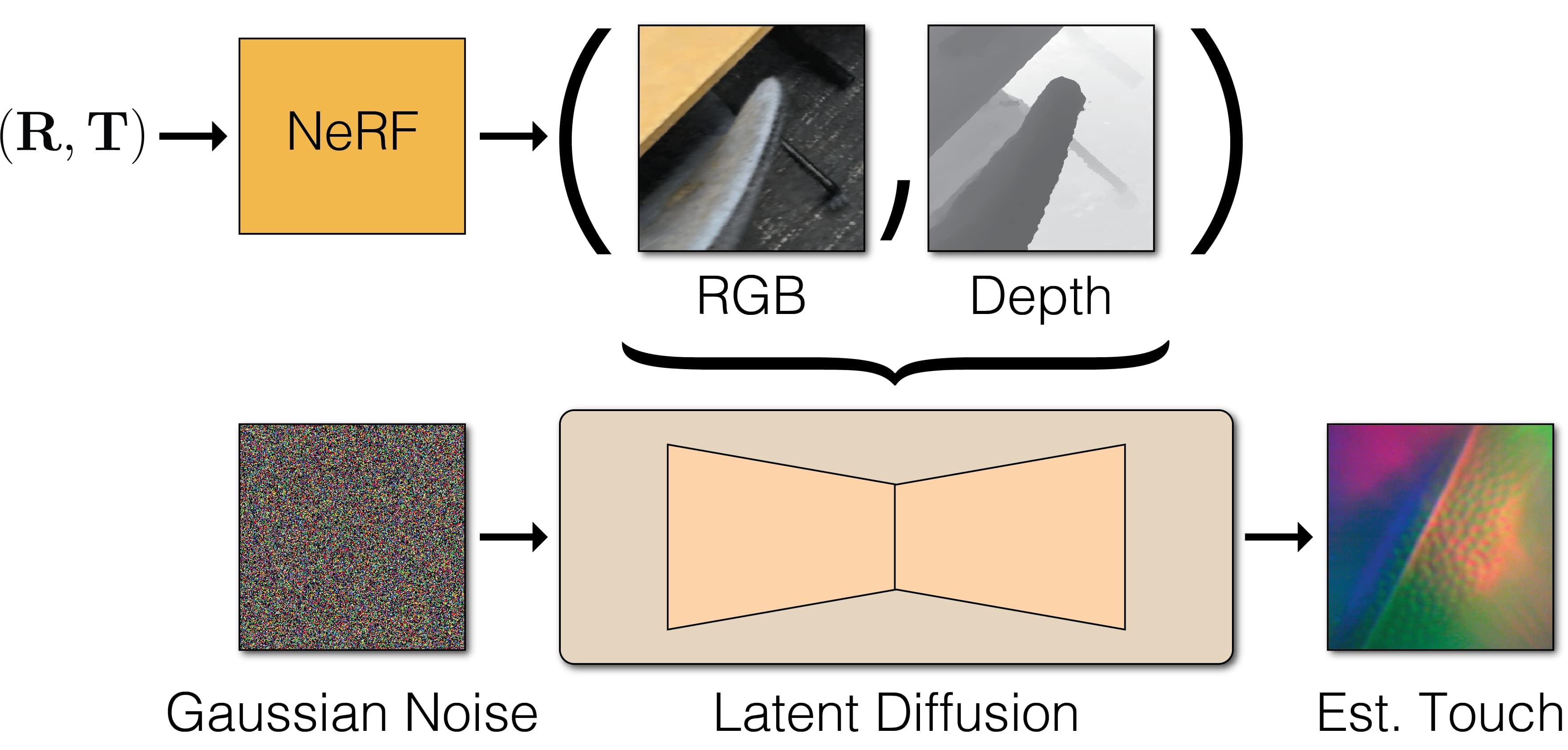
Dense Touch Estimation
Queried with arbitrary 3D positions in the scene, our model generates touch samples with many details in micro-geometry of various materials.
Downtream Tasks
Tactile Localization
Given a tactile signal and a visual image, we ask the question: what part of this image feel like this? To do this, we first train a contrastive model that maps the visual and tactile signals into a shared embedding space. Next, we split the visual image into patches and compute the similarity between each patch and the tactile signal, which is plotted as a heatmap. The heatmaps show that our model successfully cpatures the correlations between the visual and tactile data.

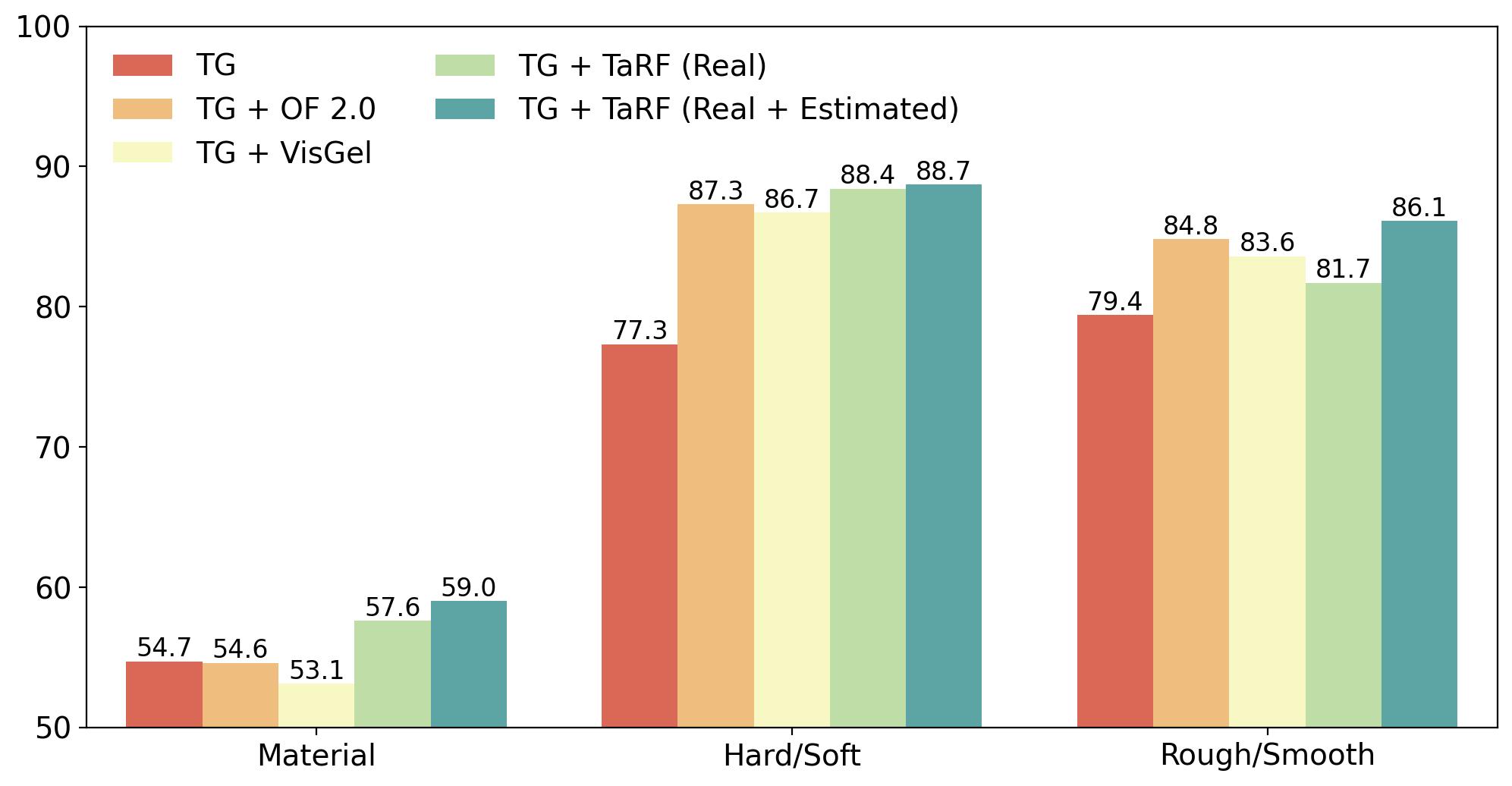
Material Classification
We investigate the efficacy of our TaRF representation for understanding material properties. We follow the formulation by Yang et al. , which consists of three subtasks: (i) material classification, (ii) softness classification and (iii) roughness classification. Combining our dataset with the original data improves the effectiveness of pretraining, and adding estimated touch signals further achieves high performance on all the three tasks. This indicates that not only does our dataset covers various materials but also the diffusion model captures distinguishable and useful patterns.
Related Works
This project is highly related to the previous work Touching a NeRF, which also estimates touch from NeRF representation using object-centric data collected from robots.
BibTeX
@article{dou2024tactile,
title={Tactile-Augmented Radiance Fields},
author={Dou, Yiming and Yang, Fengyu and Liu, Yi and Loquercio, Antonio and Owens, Andrew},
journal={arXiv preprint arXiv:2405.04534},
year={2024}
}